Wie funktioniert eigentlich generative KI?
ChatGPT, generative KI und Co
Generative KI ist in aller Munde. Als OpenAI vor 2 Jahren mit ChatGPT online ging, war das ein großes "WOOOW", das durch Internet, Fachpresse und Technologie-Influencer ging. Eine vorher nicht dagewesene Qualität an dynamischer Contentgenerierung - Wort wie Bild - war auf einmal möglich. Start-ups mit innovativen Produkten sprossen links und rechts aus dem Nichts.
Der Akt der Contentgenerierung selbst wurde infrage gestellt. Und eine Menge kreativer Berufe verloren anscheinend über Nacht ihre Daseinsberechtigung. Aber was steckt hinter dieser nahezu magischen Technikrevolution? Wenn man genau hinschaut, stellt sich heraus: Algebra und Geometrie, die wir alle im Mathematikunterricht hatten.
Vektoren und "Embeddings"?
Die Grundlage warum ChatGPT und vergleichbare Tools verstehen "was wir meinen" sind sogenannte Embeddings.
Ein Embedding ist ein Fachterminus für einen Vektor. Wie wir uns aus dem Mathematikunterricht erinnern (oder nicht, nicht schlimm) ist ein Vektor, also ein Punkt im 3-dimensionalen Raum (in der X-, Y- und Z-Achse), der die Position im Verhältnis zum Zentrum des gedachten Diagramms genau definiert. Wenn man diese 3 Zahlen für die jeweilige Achse dann noch mit positiven oder negativen Zahlen beschreibt, kann man sogar die Richtung, in der sich dieser Vektor bewegen würde, bestimmen.
Videospiele, aber auch Software für das Design von Maschinenteilen oder zur Berechnung der Statik eines Gebäudes, benutzten diese Technik seit Ewigkeiten. Selbst die Bewegung und Tendenz von Kursen am Aktienmarkt werden mit einer Art Vektor beschrieben.
Embeddings sind nun Vektoren mit mehr als 3. Dimension (X-, Y- und Z- Achse), sondern mit 100en oder gar 1000en Dimensionen (Zahlen/Achsen). Diese Embeddings definieren damit die Bedeutung in fast allen Facetten eines Wortes, Begriffes oder Satzes in unserer natürlichen Sprache.
Häh, Embeddings machen was?
Embeddings wurden schon lange vor der KI als Möglichkeit erfunden, um Worte, Phrasen und Sätze als Zahlen - und damit von Computern verarbeitbar - abzubilden. Schon in den früheren Jahren der Computer gab es Ansätze hierfür und seit den 2000ern haben die "Bayes" und "Word2Vec" Algorithmen - z. B. in der Erkennung von Spam-E-Mails - ihre Verwendung gefunden.
Aber mit dem Fortschritt der modernen Hardware, namentlich von Grafikkarten, die eigentlich für Videospiele gedacht waren, wurden neuronale Netze möglich, welche mit großen Datenmengen trainiert erstaunlich schnelle Ergebnisse liefern konnten. Und somit sehr viel detailliertere Kategorisierungen von Worten und Phrasen als Embedding ermöglichen als das vorher noch denkbar gewesen wäre.
Und was ist nun ein neuronales Netz?
Einfach ausgedrückt ist ein neuronales Netz ein Versuch der Abbildung der Denksysteme, eines (menschlichen?) Gehirns.
Natürlich kann man noch kein menschliches Gehirn im Computer abbilden, aber die Art der Gedankenprozesse für eine einzelne Handlung - z.B. das Erkennen des Buchstabens "A" - das kann man mit einer Abfolge von Algorithmen abbilden.
Die Ausgabe dieser Algorithmen wird dann bewertet - wie wahrscheinlich ist das ein "A", das ich da sehe - und das ist dann das Training eines neuronalen Netzes. Man gibt ihm zurück "Also in diesem Fall war es ein "A"; oder eben nicht."
Auf dieser Basis ergibt sich - ganz vereinfacht ausgedrückt - dann ein neuronaler Abdruck, der zuverlässig (zu 99,9999%) ein "A" erkennen kann. Dies ist natürlich eine vereinfachte Beschreibung, mit einem Beispiel aus der Schrifterkennung von vor 20 Jahren, aber es dient der Veranschaulichung, was ein neuronales Netz im Groben macht. Und es gibt eben neuronale Netze, die darauf trainiert wurden, solche Embeddings für Worte und Phrasen zu generieren.
Schön und gut, aber was bringt einem das?
Wie wir vorher schon festgehalten haben, kann man mit Vektoren (X-,Y-, Z-Achse) rechnen. Mit einfacher Schulmathematik kann man z.B. die Distanz von 2 Objekten im 3-dimensionalen Raum zueinander berechnen: also wie weit ist meine Hand von meiner Kaffeetasse entfernt.
Das kann man berechnen in dem man z.B. ein Zentrum annimmt - meinen Mund - und die Position meiner Hand zum Mund als Vektor (X-,Y-,Z-Achse) definiert, und dann die Position der Kaffeetasse zu meinem Mund (X-,Y-,Z-Achse).
Nun kann man mit einer Kosinusberechnung die Distanz zwischen meiner Hand und der Kaffeetasse berechnen. Wir erinnern uns: Der Kosinus ist die Distanz zweier Schenkel eines Winkels. (Ich weiß, es ist lange her.)
Das Schöne ist nun, diesen mathematischen Formeln ist es egal, ob wir das in einem normalen 3-dimensionalen Raum machen, oder eben in einem erfundenen 1500-fachen dimensionalen Raum (also 1500 X-, Y- und Z-Achsen).
Und das bedeutet nun praktisch?
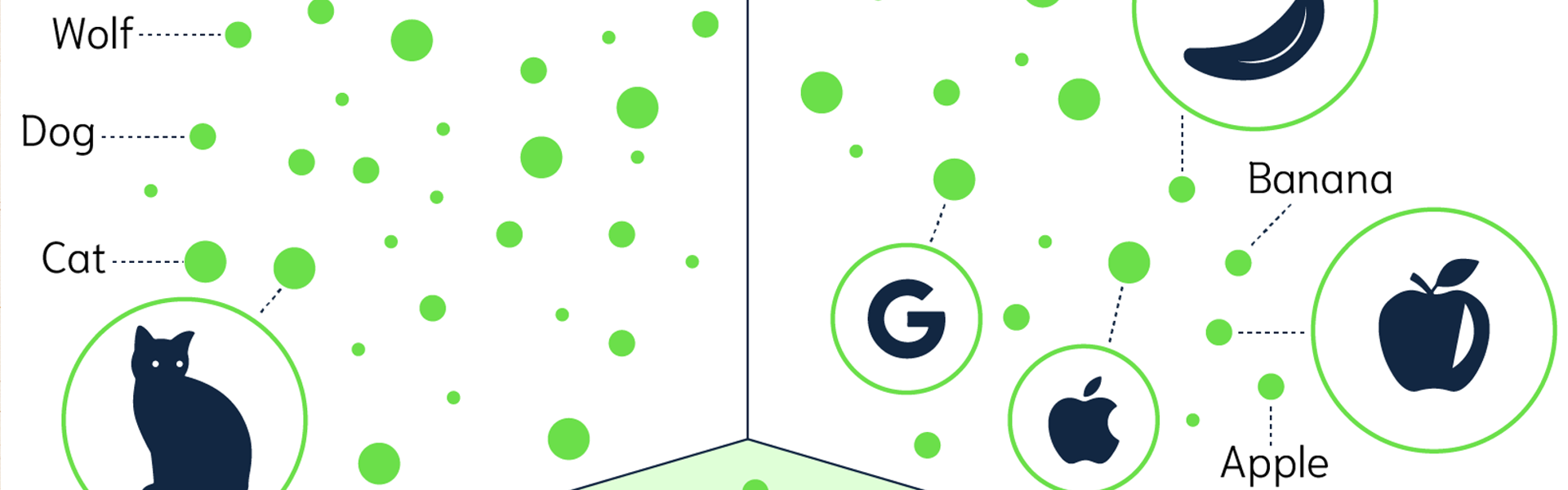
Praktisch bedeutet das, dass wir die Distanz von Worten und Phrasen zueinander berechnen können. Also wie nahe ist das Konzept des Wortes "Katze" zum Konzept des "Bild einer Katze". Oder wie nah ist das Konzept des Wortes "Katze" und dem des Wortes "Hund"? Und was ist weiter weg von Katze, Hund oder Wolf?
Das alles können wir mit einfachen schul-mathematischen Formeln berechnen, sobald wir die Embeddings dieser Worte, Phrasen oder besser Konzepte errechnet und gespeichert haben.
Das Ganze geht so weit, dass man, als Beispiel, das Embedding für das Wort/Konzept Frau und das Wort/Konzept Monarch addieren kann. Und wenn man dann für dieses Ergebnis dann die Distanz zum Wort/Konzept von Königin berechnet, erkennt man, dass diese Punkte fast identisch sind.
Und so machen das dann ChatGPT und Co?
Ja, genau. Was man als Mensch dann eingibt in den Chat, das wird umgewandelt in ein Embedding. Und basierend darauf wird dann nach vergleichbaren Inhalten gesucht, oder es wird über mehrere Zufallsgeneratoren der beste Treffer erarbeitet.
Auch bei der Bildgenerierung oder dem Erkennen von Bildinhalten wird geschaut, wie nahe die Beschreibung eines Bildes zum eingegebenen Text ist, oder ob man Bilder findet, die sehr nahe am Embedding für das angefragte Bild sind und welche Beschreibung an diesem Bild hing.
Man erkennt hierbei - und das nur am Rande - wie wichtig die SEO und Accessibility Bestrebungen der letzten 10 Jahre für Anbieter wie OpenAI waren, damit man diese neuronalen Netze sinnvoll trainieren konnte. Hätte es diese Bestrebungen nicht gegeben, dann wäre der heutige Stand der generativen KI nicht möglich gewesen!
Das ist schon ziemlich interessant, kann ich das auch für meine Daten einsetzen?
Ja! Diese Technologie kann für die eigenen Daten, Dateien und Datenbanken eingesetzt werden!
Beispielsweise kann man große Mengen von Inhalten damit kategorisieren, um ein Grundlevel an Kategorisierung zu bekommen.
Oder man kann die Qualität von Übersetzungen automatisiert testen. Die Sprache, wenn man die Worte Königin und Queen anschaut, ist ein minimaler Faktor, da beides dasselbe Konzept ausdrücken!
Oder man kann Produktempfehlungen versuchen, die nicht nur auf "von Hand" gepflegten Empfehlungslisten basieren, sondern auf konzeptioneller Ebene zusammenpassen. Natürlich kann man auch die Empfehlungslisten damit erstellen, um sie danach von Hand nachzupflegen. Sozusagen als "Baseline". Oder man kann eine Suche etablieren, die nicht stur nach Wortstämmen in Stichworten sucht, sondern eben nach der "Natur" der Stichworte auf konzeptioneller Ebene.
Wie geht das technisch?
Technisch gesehen werden hierbei üblicherweise Paragrafen oder Absätze zu Diensten wie OpenAI oder Google Vertex AI geschickt, welche dann in Bruchteilen einer Sekunde ein Embedding produziert, welches auf dem (Web-)Server zur Weiterverarbeitung gespeichert wird.
Dafür gibt es spezielle Datenbanken, aber es gibt auch Bestrebungen das diese Art von Daten nicht nur in handelsüblichen Datenbanksystemen wie MySQL oder PostgreSQL (mit einer davon läuft garantiert Ihre Webseite) gespeichert werden können, sondern auch logisch in einer Abfrage verarbeitet werden können.
Wie ist das mit der DSGVO?
Seien wir mal ehrlich, OpenAI und Google Vertex AI bieten diesen Dienst sehr günstig an, wir sprechen hier von Kosten im Millicent Bereich für ein Embedding eines Paragrafen.
Das machen diese Firmen natürlich, weil sie Daten brauchen! Nur mit mehr Daten können ihre Dienste wie ChatGPT besser werden. Das bedeutet, so viel wie möglich Embeddings zu produzieren. Daraus kann man schließen, dass man dort nicht Kundendaten oder firmeninterne Dokumente einspielen sollte, da diese dann für die Contentgenerierung verwendet werden würden.
Für allgemein öffentliche Inhalte wie Produktbeschreibungen, News oder Webseiten-Inhalten ist das sicher unproblematisch, aber wer diese Technologie auch für firmeninterne Dokumente und Kundendaten anwenden will, dem kann auch geholfen werden.
Es gibt dann immer noch die Möglichkeit, sich einen Server ins Haus zu stellen, der den Anforderungen genügt (viel Speicher, große Grafikkarte) oder man kann sich so einen Server auch bei Hostern wie Hetzner mieten. Für diese Anwendungsgebiete bieten sich die sogenannten LLAMA's an, das sind die KI's, welche von Meta (Facebook) als OpenSource veröffentlicht werden und auf privaten Computern ohne weitere Verbindung zu externen Anbietern betrieben werden können.
Kann Sudhaus7 mir dabei helfen?
Ja, bei Sudhaus7 sind Sie genau richtig! Unsere Experten unterstützen Sie bei der Integration generativer KI in Content-Management-Systeme wie TYPO3 oder WordPress. Gemeinsam entwickeln wir passgenaue Lösungen, um Ihre eigenen Daten effizient und innovativ mit dieser Technologie zu nutzen.
Kontaktieren Sie uns – wir beraten Sie gerne!